Create an Exact Data Match Identifier
Exact Data Matching (EDM) is a data classification and matching technique that effectively detects data loss incidents involving sensitive records maintained and stored in a structured data format. EDM is designed to help protect sensitive data by fingerprinting data instead of leveraging pattern matching techniques.
Umbrella performs Exact Data Matching using an EDM template, which you create by uploading a plain text CSV file that describes the fields to be matched, and choosing an EDM type for each field described in the CSV file. You must also specify which fields are required for a match, and their priority. Once the EDM template is created, you will obtain an ID for it from the Umbrella UI.
You must then download the DLP indexer and run the indexer against your data records using the EDM template. The DLP indexer validates records against the template and generates hash fingerprints for those records, creating an EDM.
Once you have run the indexer, you will have an Exact Data Match Identifier associated with the documents. You will then be able to:
- Create a Data Classification that uses the EDM as a custom data identifier (as described in Create a Data Classification or Copy and Customize a Built-In Data Classification).
- Create a DLP rule that uses the Data Classification including that EDM Identifier. (For more information on DLP rules, see Manage the Data Loss Prevention Policy.)
With these configurations in place, Secure Access will be able to monitor and/or block transmission of structured files containing records that match your indexed data. Matching records meet the criteria you establish when you create the EDM template.
Table of Contents
Prerequisites
-
Full Admin user role. For more information, see Manage Accounts.
-
JVM version 17+
-
The template CSV you upload must meet the following requirements:
- The file can not be larger than 10 KB.
- The second and ensuing rows may contain sample data; be aware, however, that this data will not be indexed unless it also appears in the source data CSV file.
-
The DLP indexer supports data files with up to 55 million records. The exact records limit is determined by the total number of columns and the number of those are of Alphanumeric type. The indexer displays the exact limit when attempting to load a file that exceeds it. If your dataset is larger than the limit, you need to split the records into multiple files. For errors received when indexing a large file, see Memory Tuning for DLP Exact Data Matching Indexer.
-
Both the template and source data CSV files must meet the following requirements:
- A multi-term (multi-word) field can contain a maximum of 6 space-separated words.
- The data file must contain only 1 byte or 2 byte UTF-8 encoded characters.
- The first row of data must have between 1 and 50 fields and each row must have the same number of fields.
- The first row of data must specify the name of each field, and each value must be unique.
- Data in the second and ensuing rows must comply with the EDM field types and supported formats (see Exact Data Match Field Types).
- The field names in the sample data template must match the field names in the actual data source file. The field names must appear in the same order in both files.
Caution: Do not create, edit, or view the template or source data CSV file using Microsoft Excel, as this may corrupt the file. Use a text editor.
Note: If any of the values provided in the source file to the DLP indexer fail to be validated as per the supported format, then the DLP indexer will skip that record and proceed with indexing the remaining records. The indexer also behaves in this manner for any records that may exceed the template-defined fields, and for empty rows or records with empty primary values. The position of the skipped records in the file will be provided as part of the output of the DLP indexer.
The following procedure uses the following example CSV file for both the template and indexed source data:
Email,SSN,Passport number - US,Credit card number
[email protected], 113011111,123456789USA1234567U1234567, 5205105105105109
[email protected], 248257990,123456789USA1234567U1234567, 4532237384050172
[email protected], 363265019,123456789USA1234567U1234567, 4532549977031249
[email protected], 417279936,123456789USA1234567U1234567, 4539157470627290
Procedure
- Navigate to Secure > Settings > Data Classification > Exact Data Matches and click ADD EXACT DATA MATCH IDENTIFIER.
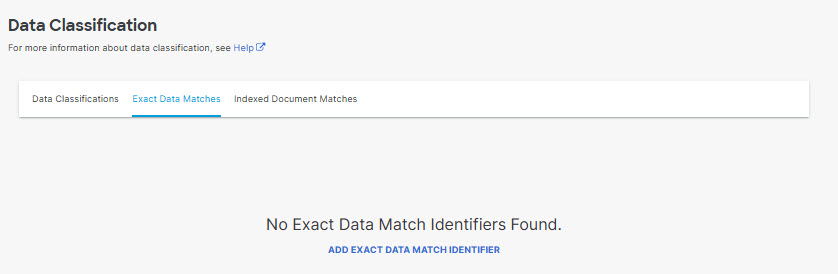
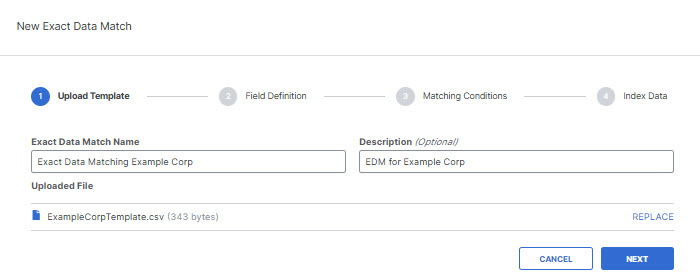
- Provide a name and description for the exact data match, then upload sample data and click Next.
Note: Do not upload any real data in the CSV. Use only sample data for the template.
- From the drop-down menu, choose the type of data of each field.
The available field types are described in Exact Data Match Field Types:
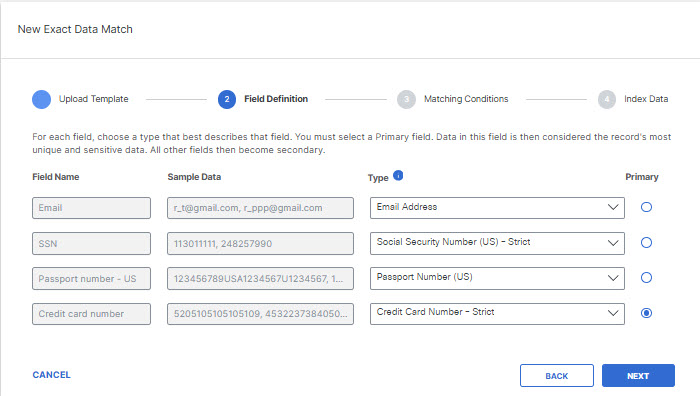
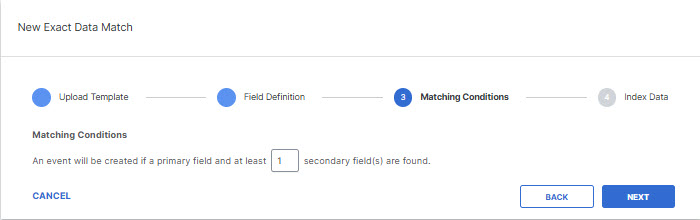
- Select the Primary field that must be found with other data fields for the identifier to match and click Next. The primary field should be the field in the record to always match. The secondary fields are the number of fields in the record that should be present with the primary field to match.
- Enter the minimum number of secondary fields required to be found within 10 terms of the primary field for a match. You can have no secondary field, or up to as many fields in the record that are not the primary field. For example, if at least 3 secondary fields are required, then the identifier will trigger an event only when 3 or more additional fields are found with the primary field. If the .csv file has only 1 column, then the secondary option is greyed-out and automatically set to 0. Click Next.
Note: The secondary fields must each be a different identifier.
- Click the download icon to download the DLP indexer. Then click Save.
Note: You can click on Command Line Parameters to view information about the command line arguments required to run the indexer.
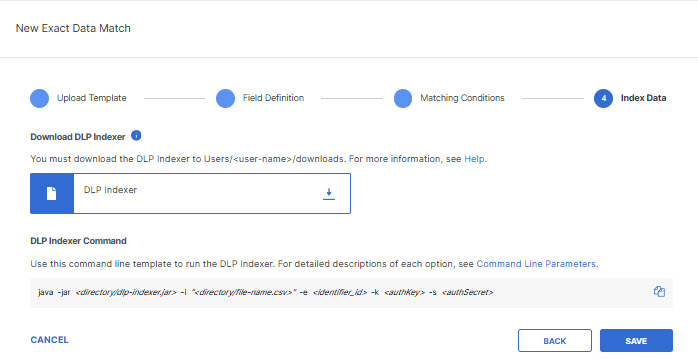
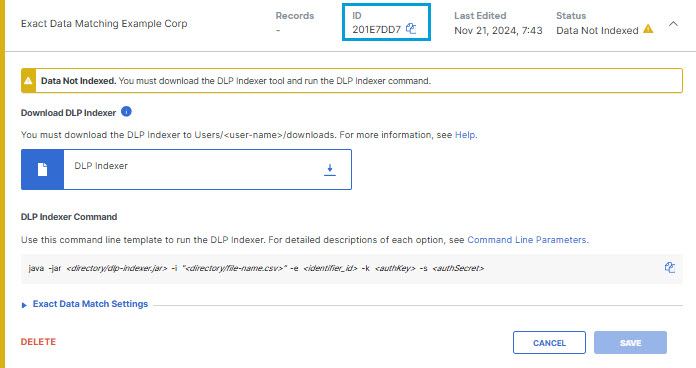
- The EDM Identifier now has a status of Data Not Indexed. You can expand the listing to view the details about the EDM Identifier. When the EDM identifier status is Data Not Indexed, you can edit the field types, the primary field selection, and the matching conditions, but the EDM Identifier cannot be added to a data classification. Make note of the ID for th EDM Identifier; you will need it to run the DLP indexer.
Note: The display page does not display the full EDM identifier ID; use the Copy icon to copy the ID
- Create an API key and secret for the EDM data indexer.
a. Navigate to Admin > API Keys and click Open API Keys.
b. Click Add and provide an API Key Name and Description for the API Key.
c. Select Policies > DLP Indexer for the scope and choose Read/Write for the permissions. Then click Create Key.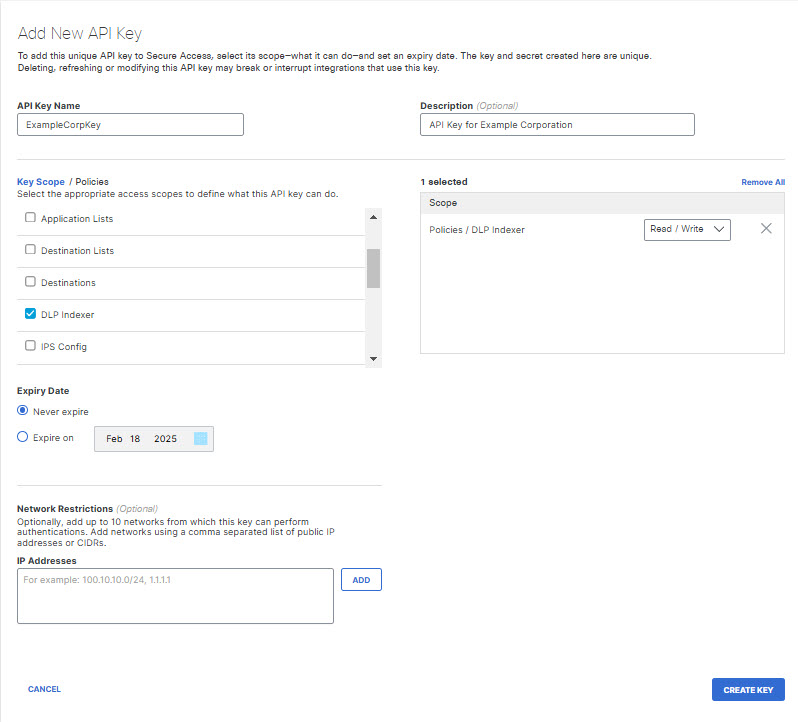
d. Copy and save the API Key and Secret somewhere safe, as you will need them to run the DLP Indexer.

- Click ACCEPT AND CLOSE.
- Use the Secure Access DLP Indexer to index your data records. For more information on the indexer, see Index Data for an EDM.
a. Move the indexer from the Downloads folder to a convenient location, such as the folder where the data records are stored.
b. Run the indexer in a terminal window with the following command:
java -jar <directory_path>\dlp-indexer.jar -i "<directory_path>\<source_file>.csv"
-e <edm_template-id> -k <authKey> -s <authSecret>where:
- <directory_path>\dlp-indexer.jar —the relative path to the location of the DLP indexer
- "<directory_path>\<source_file>.csv" —the relative path to the csv spreadsheet with the actual data records
- <edm_template-id> —the ID of the EDM Identifier retrievable from the Umbrella UI (see Step 7)
- <authKey> —the API Key previously saved at Step 8d
- <authSecret> —the API Secret previously saved at Step 8d
The EDM Identifier now has a status of Data Indexed.
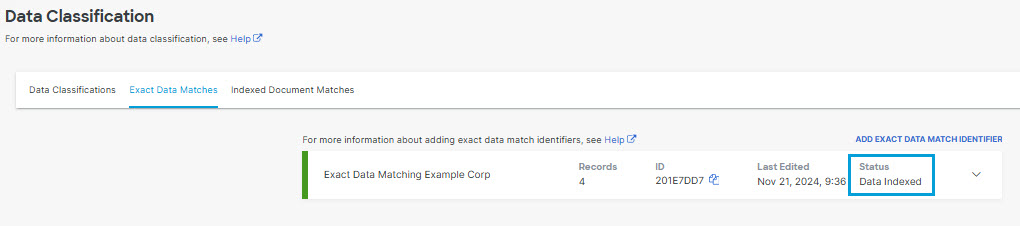
The EDM Identifier now has a status of Data Indexed.
Note: When the EDM has a status of Data Indexed, you can add the EDM to a data classification but you can not edit the field types, primary field selection, or matching condition.
If you update your source file with new or changed records, you need to run the DLP indexer again on that file using the same EDM Identifier ID, API Key, and API Secret. This ensures that policies configured to use the EDM Identifier are updated to reflect the new data fingerprints. For more information, see Update the Indexed Data Set Periodically.
Delete or Edit a Classification < Create an Exact Data Match Identifier > Index Data for an EDM
Updated 8 months ago